很多小问题可以通过 Code Snippets 插件来解决
第一轮
-
首页缺少 RSS 自动发现链接
-
Feed 里有两个内容警告
W3C Validator 认为 RSS 有效,但提示:
- 文章标题 两款think鼠标测评-thinkplusM30&thinkplusT60X 里的 & 容易被当成 HTML/entity。建议标题里把 & 改成 和、+ 或空格。
- 文章 2025 Air手机进店摸摸有感... 的正文里有 (<6mm),在 content:encoded 的 HTML 里 <6mm 会被解析成非法标签。建议改成 小于 6mm 或 <6mm。
- 订阅地址建议直接用 /feed
https://benli06.site/rss 能用,但它是跳转地址。更标准的 WordPress RSS 2.0 地址是:
解决方法
- 在 Code Snippets 里 add new script, 标题可填
Enable RSS autodiscovery
add_action('after_setup_theme', function () {
add_theme_support('automatic-feed-links');
});
add_action('wp_head', function () {
echo '<link rel="alternate" type="application/rss+xml" title="' . esc_attr(get_bloginfo('name')) . ' RSS Feed" href="' . esc_url(get_feed_link('rss2')) . "\" />\n";
}, 2);运行范围选择 Run snippet everywhere 即可。
- 手动修改文章内容。
- 在阅读器里填 /feed 链接。
第二轮
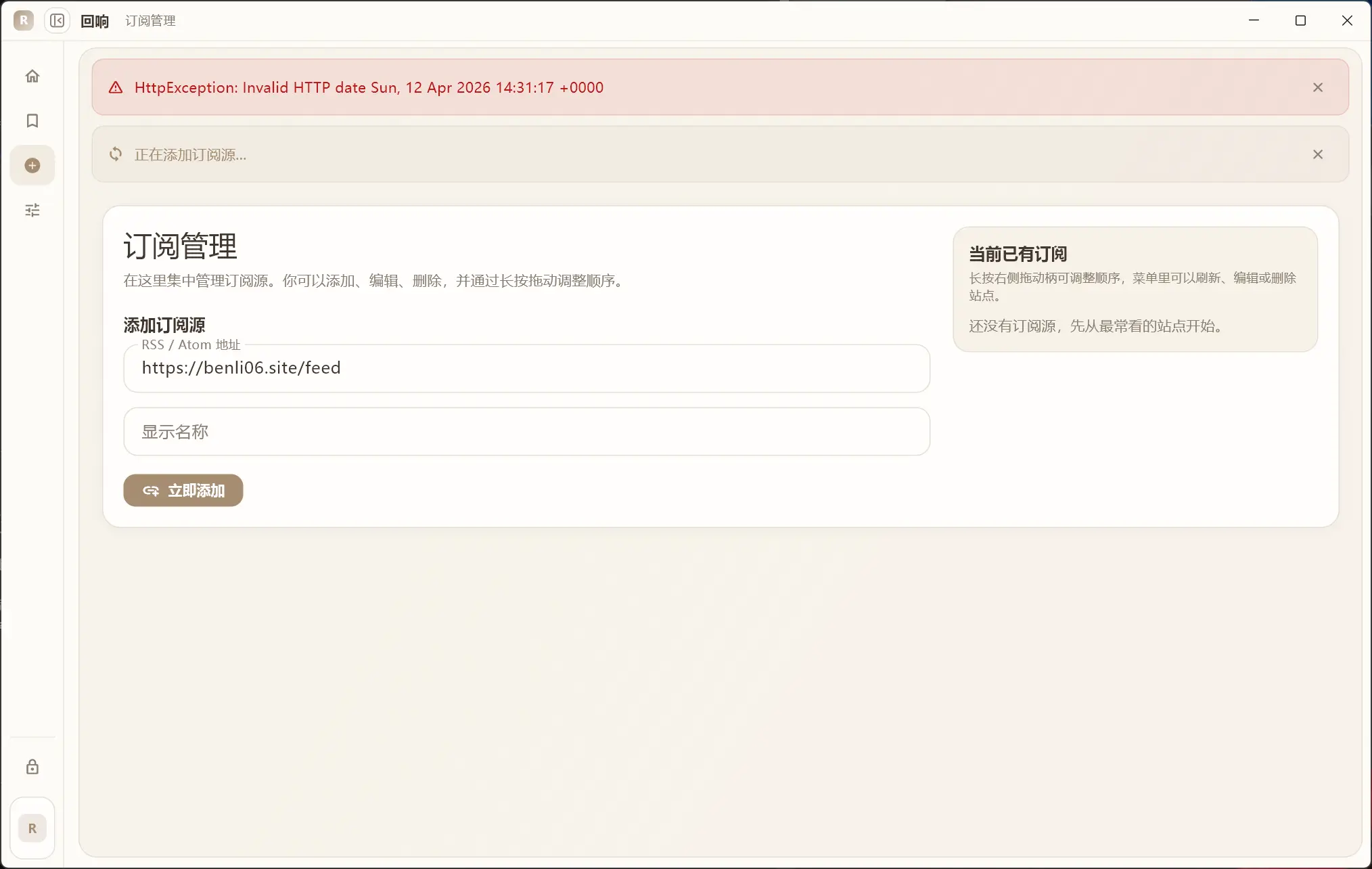
这是因为部分新式的 RSS feed 将文章发布时间戳的 GMT 改为了 +0000
我们需要做的是替换 +0000 为 GMT ,以获得更好的兼容性。
在 Code Snippets 里新建脚本,标题随意。
add_action('send_headers', function () {
if (!is_feed()) {
return;
}
$last_modified = get_lastpostmodified('GMT');
$timestamp = $last_modified ? strtotime($last_modified . ' GMT') : time();
header('Last-Modified: ' . gmdate('D, d M Y H:i:s', $timestamp) . ' GMT', true);
}, 999);
add_action('template_redirect', function () {
if (!is_feed()) {
return;
}
ob_start(function ($buffer) {
return preg_replace_callback(
'#<(lastBuildDate|pubDate)>([A-Z][a-z]{2}, \d{2} [A-Z][a-z]{2} \d{4} \d{2}:\d{2}:\d{2}) \+0000</\1>#',
function ($matches) {
return '<' . $matches[1] . '>' . $matches[2] . ' GMT</' . $matches[1] . '>';
},
$buffer
);
});
}, 0);
Q: 有什么副作用
A: 副作用很小,但这不是“长期优雅解”。
把 RSS 里的 +0000 改成 GMT 本身没问题:
Sun, 12 Apr 2026 14:31:17 +0000 Sun, 12 Apr 2026 14:31:17 GMT 这两个都表示 UTC 时间。大多数 RSS 阅读器都能识别,GMT 反而更兼容一些老旧或严格的解析器。所以对订阅内容、排序、发布时间基本没有影响。
可能的副作用主要是:
- 这是输出层替换
它会在 WordPress 输出 feed 时对 XML 文本做一次正则替换。只要 snippet 只在 is_feed() 下运行,影响范围就限制在 RSS/Atom feed,不会影响网页正文。 - 如果以后某个插件也修改 feed 输出
可能会和缓存插件、Feed 插件、SEO 插件的 feed 处理叠加。但这个替换很窄,只处理和 ,风险不大。 - 如果 feed 不是 UTC
这个写法只替换 +0000。你的站点现在输出的是 +0000,所以没问题。如果以后 WordPress 改成 +0800,这段代码不会替换,也不会误改时间。
第三轮
Q: 为什么 RSS 里只有 10 篇文章?
A: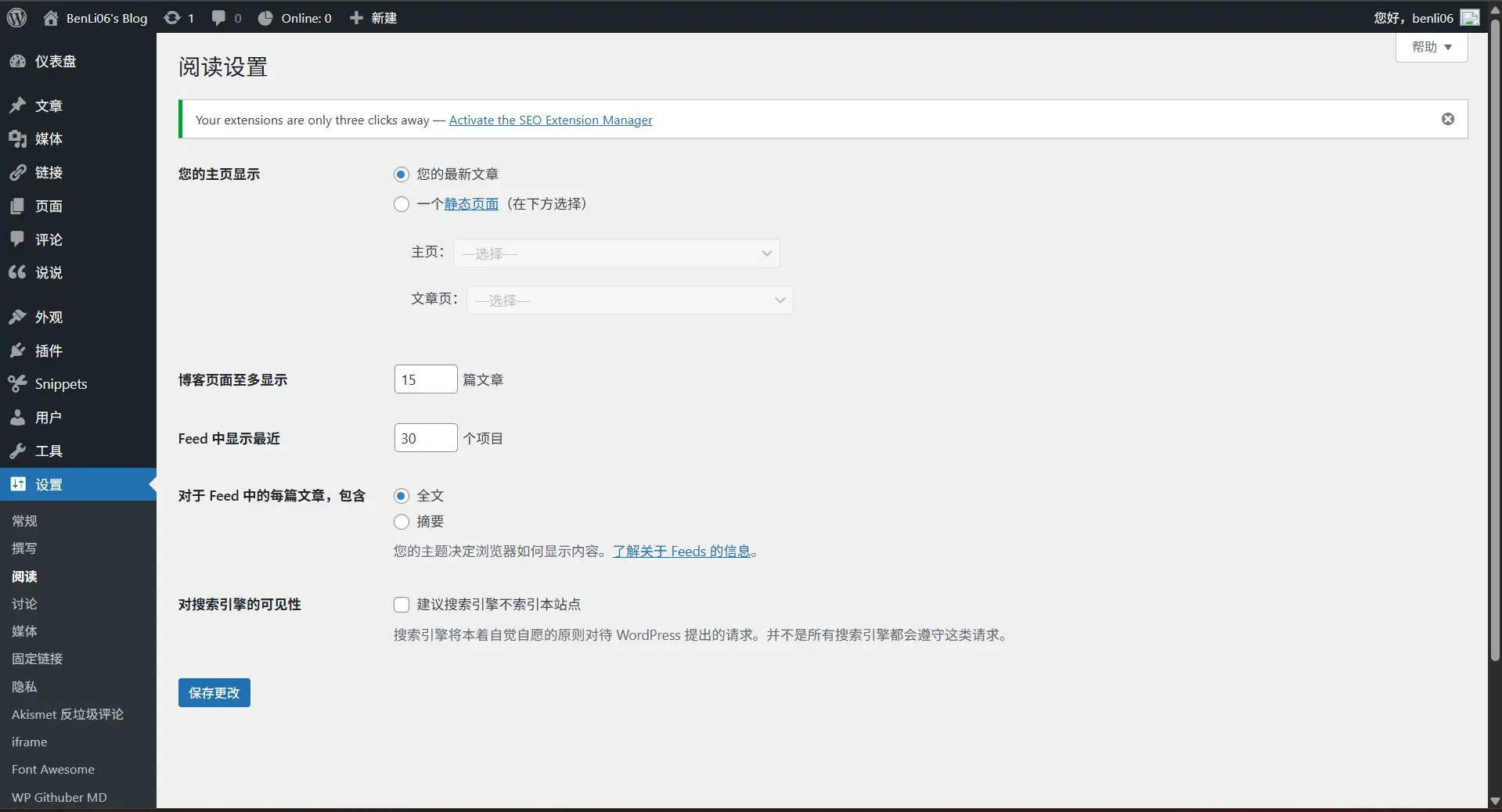
在 WordPress 仪表盘,首页 > 设置 > 阅读,这里调整 Feed 中显示最多的文章量。
Q: 为什么不显示全文?
A:不显示全文有多种可能情况。一种是设置了只显示摘要,一种是全文被截断(一般是 SEO 插件导致的)。
对于第一种,在 WordPress 仪表盘,首页 > 设置 > 阅读,这里可以设置对 Feed 中的文章,包含 全文 或 摘要。
对于后一种,打开你的 SEO 插件设置,搜索 订阅供稿设置 或 feed,取消勾选 将提要条目转换为摘录? , 另外,最好开启 允许索引提要吗?.
第四轮
Q: 为什么出现format-exception
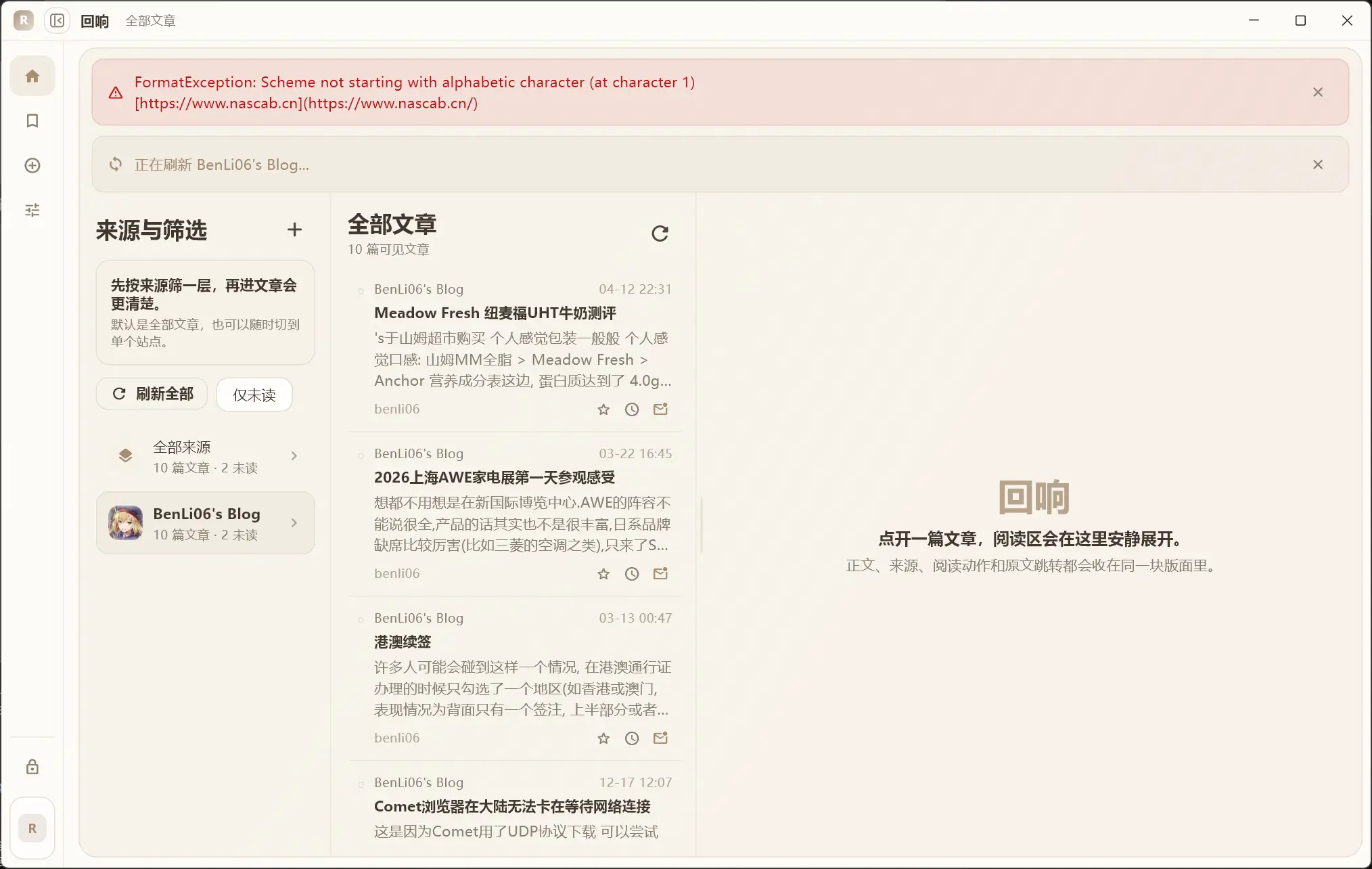
可以给 AI 检查 feed 内容。比如我是有一个笔误,在markdown格式中,在  中的 alt 填作了一个链接。
第五轮
Q: 现在,有的rss阅读器无法从我的链接抓取feed,思考原因
A: 原因基本确定:当前的 https://benli06.site/feed 不是合法 XML,所以有些 RSS 阅读器抓不到。
我刚检查到:
/feed返回200 OKContent-Type是正确的:application/rss+xml- 首页也已经有 RSS 自动发现链接
- 但 W3C Feed Validator 和本地 XML 解析都报错:
XML parsing error: not well-formed (invalid token)
invalid character: 0x0B出问题文章是:
2026上海AWE家电展第一天参观感受
https://benli06.site/archives/359里面有 4 个非法控制字符 0x0B,也就是垂直制表符。它看起来像空白/换行,但在 XML 1.0 里非法。严格的 RSS 阅读器会直接拒绝整个 feed;宽松的阅读器可能会跳过,所以你看到“有的能抓,有的不能”。
你可以这样修:
- 去 WordPress 后台编辑这篇文章:
archives/359 - 在这些位置附近重新删掉并手打换行:
- “下血本了.” 后面
- “没松下和LG的舒服.” 后面
- 其他从外部复制粘贴过来的异常空白处
- 保存文章
- 清 Cloudflare 缓存:
https://benli06.site/feed
https://benli06.site/rss更稳的做法是在 Code Snippets 里给 feed 输出加一道清理非法 XML 字符的过滤:
add_action('template_redirect', function () {
if (!is_feed()) {
return;
}
ob_start(function ($buffer) {
return preg_replace('/[\x00-\x08\x0B\x0C\x0E-\x1F]/', '', $buffer);
});
}, 9999);这个只作用于 feed,会移除 XML 1.0 不允许的控制字符。修完后用这个验证:
https://validator.w3.org/feed/check.cgi?url=https%3A%2F%2Fbenli06.site%2Ffeed只要 validator 不再报 XML parsing error,严格型阅读器就应该能正常抓取。
Views: 7